
LLMs und Vektor-Datenbanken
Um die Funktionsweise von RAG-Systemen zu erläutern, ist es vorab wichtig, die Begriffe Large Language Model und Vektor-Datenbank zu verstehen. Large Language Models sind eine Art Algorithmus, der Deep-Learning-Techniken und große Datensätze verwendet, um Inhalte zu verstehen, zusammenzufassen, zu generieren und vorherzusagen. Gefüttert werden diese Modelle mit den sogenannten Trainingsdaten, auf deren Basis der Output generiert wird. Als Schnittstelle zwischen Nutzer und LLM fungieren sogenannte KI-Chatbots wie ChatGPT, Google Gemini und Google AIOs (das Optimieren auf Platzierungen in Chatbots nennt man übrigens LLMO). Je ausführlicher und detaillierter die Trainingsdaten, desto leistungsfähiger das Modell. Zum Vergleich: ChatGPT 3 wurde mit 175 Milliarden Parametern gefüttert, während ChatGPT 4 mit 100 Billionen Parametern gefüttert wurde. Entsprechend leistungsfähiger ist ChatGPT 4.
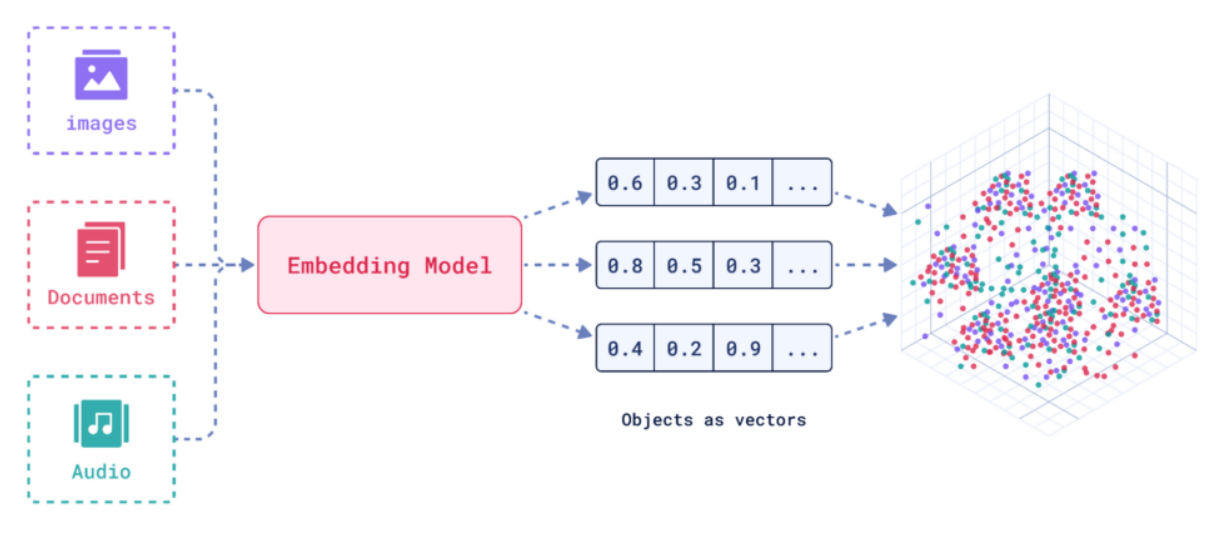
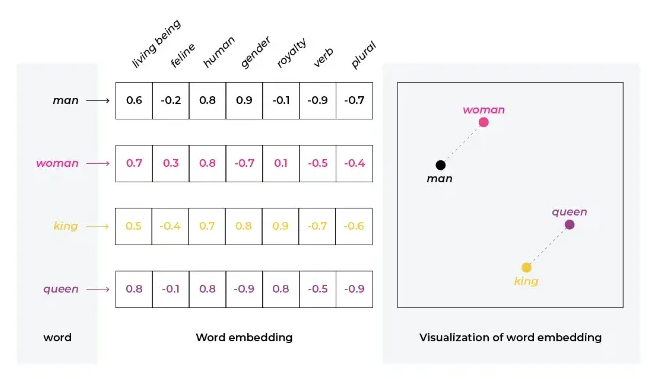
Die hier erläuterten Trainingsdaten werden über ein KI-basiertes Einbettungsmodell auf Basis ihrer Bedeutung und ihres Kontextes in Vektor-Embeddings, also mehrdimensionale Punkte in einem Koordinatensystem, umgewandelt. Mithilfe der Vektoren lassen sich unterschiedliche Datentypen wie Bilder, Dokumente oder Audio-Dateien miteinander vergleichen, da die Assets als Vektoren im mehrdimensionalen Raum dargestellt werden können.
Somit sind alle Dateien trotz ihrer unterschiedlichen Ausgangssituation dem gleichen mathematischen System untergeordnet, was sie beispielsweise über den euklidischen Abstand oder die Kosinus-Ähnlichkeit vergleichbar macht. Je näher sich die Assets im vektoriellen Raum sind, desto ähnlicher sind sie sich bezüglich ihrer semantischen Bedeutung.
Vom LLM zum RAG-System
Als Basis für jedes RAG-System fungiert ein LLM. RAG-Systeme sind im Endeffekt nichts anderes als LLMs, deren standardmäßige Vektor-Datenbank um weitere Daten ergänzt wurde. Als Beispiel: Wenn mein RAG-System als Kochassistent fungieren soll, könnte man ein gutes Kochbuch als PDF in die Trainingsdaten integrieren. Frage ich das System nun nach Rezeptvorschlägen, wird bevorzugt ein Rezept aus dem in der Vektor-Datenbank hinterlegten Kochbuch geliefert.
Ein etwas komplexeres Beispiel wäre ein Onboarding-System für neue Mitarbeiter in einem Unternehmen. Man könnte hier diverse interne Unternehmensdokumente integrieren, die nicht in den üblichen Trainingsdatensätzen von LLMs enthalten sind. Über das RAG-System könnten diese Dokumente auf Basis eines Systemprompts aufbereitet und neuen Mitarbeitern, abhängig von ihrer Rolle, bereitgestellt werden.
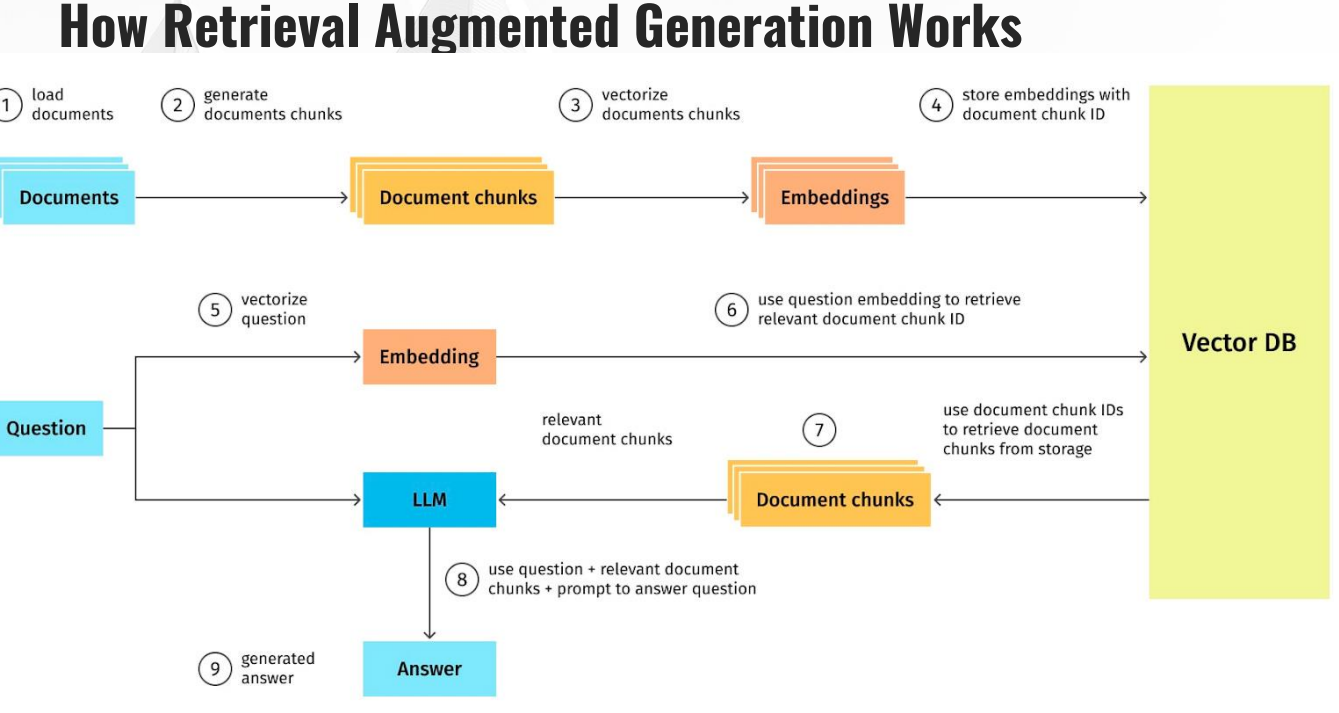
Etablierte Beispiele für RAG-Systeme sind Custom-GPTs, also konfigurierte Versionen von ChatGPT. Mit dieser Funktion erlaubt es OpenAI, dass man auf Basis des LLMs separate Vektor-Datenbanken anlegt und eine spezifische Aufgabe für den Assistenten definiert. So gibt es beispielsweise öffentliche Custom-GPTs, die beim Programmieren oder der Datenanalyse unterstützen.
RAG-Systeme entwickeln
Um ein RAG-System für die eigenen Zwecke zu entwickeln, sollte man zunächst den Use Case definieren. Wobei genau soll mich das System unterstützen?
Sobald der Use Case geklärt ist, sollte man sich auf ein Tool bzw. LLM festlegen. Die einfachste Variante wäre wohl ein Custom GPT; hier gibt es allerdings Bedenken bezüglich Datenschutz. Möchte man das RAG-System beispielsweise auf der eigenen Website öffentlich zugänglich machen, sollte das Tool DSGVO-konform sein. Hierfür wäre ein herkömmlicher Custom GPT nicht ausreichend. Als Workaround bieten sich KI-Plattformen wie Localmind an, welche die LLM-Software auf in Deutschland befindlichen Cloud-Servern hosten.
Im nächsten Schritt gilt es, die benötigten Trainingsdaten in einem passenden Dateiformat zu kompilieren und hochzuladen. Welche Assets genau benötigt werden, hängt vom jeweiligen Use Case ab.
Im vierten Schritt muss nun der Systemprompt erstellt werden. Hier wird definiert, welche Aufgaben der Assistent hat, wie er mit den Trainingsdaten und dem Input des Nutzers umgeht, welche Workflows bedient werden sollen etc. Der Systemprompt ist entscheidend für den Erfolg oder Misserfolg der Anwendung.
Letzter Schritt: Testing. Nachdem das RAG-System funktionsfähig ist, gilt es, den angepeilten Use Case in möglichst vielen verschiedenen Variationen von möglichst vielen verschiedenen Nutzern testen zu lassen. Früher oder später werden Unstimmigkeiten auftauchen, welche die Basis für eine erneute, sukzessive Anpassung des Systemprompts und der Trainingsdaten sind. Erst wenn nach mehreren Testläufen keine größeren Fehler mehr auftreten, ist das RAG-System fertiggestellt.
Anwendungsgebiete für RAG-Systeme
Das wohl relevanteste Anwendungsgebiet für RAG-Systeme ist die Content-Erstellung. Durch die Integration eines optimierten RAG-Systems in die Content-Erstellung lassen sich bestehende Workflows deutlich effizienter gestalten, bei gleichbleibender Qualität der Inhalte. Dabei kann das System nicht nur für komplette Fließtexte, sondern auch für einzelne Absätze oder SEO-Tags wie Meta-Titles und -Descriptions verwendet werden. Weiterhin können beispielsweise Briefings automatisch vertextet, bestehende Inhalte auf Lücken analysiert oder Abgleiche des eigenen Keyword-Sets mit dem der Konkurrenz durchgeführt werden. Dabei kann die große Schwäche von KI-Texten bezüglich Qualität, die immer gleiche Datengrundlage, durch eine personalisierte Vektor-Datenbank umgangen werden. Dieses Vorgehen hat allerdings den Nachteil, dass RAG-generierte Texte aufgrund der Halluzinationsprobleme von LLMs immer von Menschen auf Korrektheit gegengeprüft werden müssen. Selbst mit diesem zusätzlichen Schritt könnte der Zeitaufwand allerdings massiv reduziert werden.
Ein zweites Anwendungsgebiet stellen personalisierte KI-Chatbots dar. Diese können extern (beispielsweise auf der Firmen-Website) oder auch intern (beispielsweise zum Anlernen neuer Mitarbeiter) genutzt werden. Insbesondere für große Unternehmen sind Chatbots auf der eigenen Website schon länger Standard, da man hiermit Ressourcen sparen kann. Durch den Wechsel von traditioneller Chatbot-Technologie auf KI-Chatbots hat sich deren Qualität massiv gesteigert, und die Umsetzung wird auch für kleinere Unternehmen erschwinglich.
RAG-Systeme von seowerk
Sofern ihr Interesse an einem für euer Unternehmen zugeschnittenen RAG-System habt, tretet mit uns in Kontakt! Wir beraten euch gerne bezüglich Use Cases und setzen das RAG-System für euch um. Auch für andere Online-Marketing Leistungen stehen wir euch zur Verfügung.
Quellen
- Mike King: “The importance of Retrieval Augmented Generation (RAG)” (SMX Vortrag)
- https://www.computerweekly.com/de/definition/Large-Language-Model-LLM
- https://www.pixx.io/blog/was-weiss-chatgpt
- https://www.melibo.de/blog/gpt-4-revolutionare-features-und-signifikante-unterschiede-zu-gpt-3
- https://www.dotnetpro.de/backend/datenbanken/so-llms-vektordatenbanken-hocheffiziente-nlp-suchmaschinen-2903957.html
- https://medium.com/@EjiroOnose/vector-database-what-is-it-and-why-you-should-know-it-ae7e7dca82a4
- https://www.localmind.ai/
- https://openai.com/index/introducing-gpts/
- https://aws.amazon.com/de/what-is/vector-databases/
Interne Links
- LLMO: https://www.seowerk.de/news/llmo/
- Google AIO: https://www.seowerk.de/news/google-aio/
- SEO Agentur: https://www.seowerk.de/seo-agentur/
- Andere Leistungen: https://www.seowerk.de/leistungen/
